Tips For Effective Go Tests
Skipping tests is common practice, especially in startups that sacrifice testing in favor of rapid development. We all know that this is not a best practice, but yet we still do it. A great solution incorporating testing in a fast-paced SDLC is to embed testing in the lifecycle. I’ll explain the benefits of this approach and provide some practical tips.
Why
It’s counterintuitive, but I believe that when embedded testing is implemented correctly, the velocity of the development lifecycle will improve, not decline. When you write your own tests, you’re sort of the first beta tester for your code, which results in improved, decoupled, and more reliable code.
Last but not least, tests with a wide coverage build the developer’s confidence to refactor on the fly and reduce the legacy code that we really should be maintaining. This will dramatically improve code velocity and reliability.
What
First and foremost, we need to define the scope of our tests. When writing a simple utility function, it might be convenient to use a unit test that tries using valid and invalid inputs. Struggling to write a unit test for such a function might be a good opportunity to re-check our dependencies, and perhaps even rethink our design altogether.
A good example of a test that should be out of scope is when you use an external, 3rd-party email service. There’s no need to test this (you can easily do this using an E2E, but that’s a story for another blog) since we can assume it has already been tested quite well by its developers. In this case, you just need to make sure your code handles success and failure cases as you expected.
A well-defined testing scope frees up your time and enables you to direct your energies where they’re needed. And most importantly, it ensures you will not overcomplicate your tests code.
How
Testing is an endless topic, so how do we attack it? I’m going to focus on some best practices that will help you make a great return out of your testing efforts.
Testable Code
Global State
Just avoid it whenever possible. It makes parallelism cumbersome and might affect subsequent tests. Let each test initialize its own instance to work on, it may take a few additional lines of code, but I assure you it's worth it.
Configuration
Many times we find ourselves using constants like server listening ports, timeouts, paths to configurations files, and many others. Make those parameters configurable so your tests will have more flexibility. Remember that tests run as part of your package so you also have the option to include them without export to external usage.
Immutability
Make sure you have minimum side effects and mutations to the current state. For example, putting values inside environment variables can affect our subsequent test runs so we need to think carefully if we do want it.
Interfaces & Mocks
From your service perspective, you need to make sure that your code will handle external interactions correctly. Defining the behavior of the external service not only will prevent you from vendor-lock but also can be easily converted to a mock implementation that can behave just the way you want for each test. To generate the mock code you can use this tool: https://github.com/golang/mock
Test Containers
A mock is nice, but there’s nothing like the real McCoy. For a good integration test, set up your dependencies as containers whenever possible. You can find a lot of ready-to-use examples of using PostgreSQL, Redis, MongoDB, Cassandra, and more here: https://github.com/ory/dockertest.
Running a local PostgreSQL is as easy as this:

Text Fixtures & Golden Files
Tests can hold ancillary data, just put your files under a directory named testdata, the go tooling will ignore this directory.
The files can be easily accessed because go test run with the package directory as the current working directory so your code use relative paths.
It is the right place to put large textual or binary content for both inputs and expected results, which are called golden files.
Putting those files separately helps you watch and edit in the right context, for example, JSON can be formatted and highlighted using your favorite editor instead of holding it as a giant string inside the test code.
Also, by staging the test results as part of our Git repository we can track the changes on our desired result for each pull request, which is super convenient.
Table Driven Tests
Make it a rule of thumb that tests should have more than one test case. You can always check for both valid and invalid input for example but most importantly in my opinion is preparing the ground for future extensions of your test functions.
Let’s write a simple Reverse() function and write table-driven tests for it
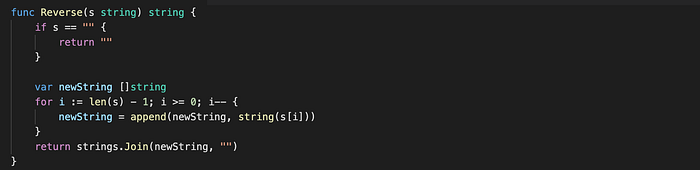

Coverage
Test coverage is a term that describes how much of a package’s code is exercised by running the package’s tests. If executing the test suite causes 80% of the package’s source statements to be run, we say that the test coverage is 80%.
Thanks to the amazing Go tooling system, it is super easy to get a summary measurement of our code. Let’s run it on our previous Reverse example:

Okay, the percentage is great and gives us a sense of how much code our tests have been covered. But we can dig deeper and identify the specific branches in our code that are not covered.
Running the following command will open the report we’ve just created in the browser and clearly displays the uncovered parts of our code:
To cover this missing case we just need to add a suitable case to our table test cases:

Running the go tool command again will result with:
Perfect! We got our code fully covered and it was super simple thanks to our table-driven test.
Summary
When implemented properly and with a purposeful scope, writing testable code will result in a clean, de-coupled, and maintainable code, without compromising on velocity. After a few cycles, you’ll wonder how you have lived without it.
References
[-] https://speakerdeck.com/mitchellh/advanced-testing-with-go?slide=6
[-] https://about.sourcegraph.com/go/advanced-testing-in-go/
[-] https://www.youtube.com/watch?v=8hQG7QlcLBk
[-] https://dave.cheney.net/2016/05/10/test-fixtures-in-go
[-] https://blog.golang.org/cover
